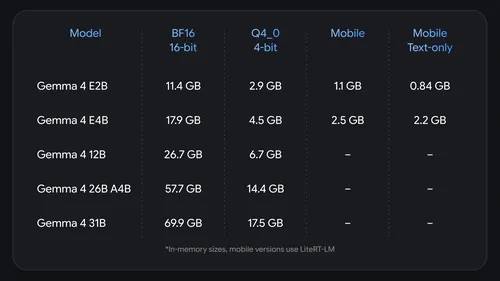
Gemma 4 QAT 来了,手机也能本地部署 QAT不是普通量化,Quantization-Aware Training是模型在训练阶段就适配低比特表示,效果接近原模型 (bfloat16),但内存占用大幅下降。 最小模型小于1GB,小设备部署没压力,我打算用它试下本地agent + RAG的效果 🔗 https://huggingface.co/collections/google/gemma-4-qat-q4-0